Die KI entwickelt sich unglaublich schnell. In dem Maße, wie die Erstellung von KI-Inhalten zunimmt, steigt auch die Notwendigkeit robuster Mechanismen zur Unterscheidung zwischen synthetischen und menschlichen Texten. Folglich haben wir den Aufstieg von KI-Inhaltsdetektoren erlebt.
Es hat sich gezeigt, dass nicht alle Inhaltsdetektoren gleich sind. Eine Fülle von Lösungen hat den Markt überschwemmt, und jede wirbt mit ihren eigenen, selbsternannten Genauigkeitsraten. Diese Statistiken sind zwar oberflächlich betrachtet vielversprechend, doch fehlt es ihnen häufig an der Transparenz und Prüfung, die erforderlich sind, um echtes Vertrauen in ihre Wirksamkeit zu schaffen.
Unser Ziel ist es, Institutionen und Unternehmen bei der Aufrechterhaltung ihrer Integrität zu helfen, und der beste Weg, dies zu erreichen, ist die höchste Genauigkeitsrate in der Branche zu bieten.
In diesem Artikel wird das neueste englische KI-Erkennungsmodell von Winston AI und die dritte Hauptversion (V3.0) mit dem Codenamen „Luka“ näher vorgestellt.
Unser Ziel ist es, die Unklarheit über die Trefferquote bei der Erkennung von Inhalten zu beseitigen. Unser Engagement für Transparenz zeugt von unserer Überzeugung, dass die Nutzer mehr verdienen als nur Versprechungen über die Wirksamkeit – sie verdienen ein Instrument, das durch transparente Daten gestützt wird.
Ein neuer Standard für Transparenz bei der KI-Detektion
Im Gegensatz zu den meisten anderen KI-Inhaltserkennungsprogrammen verpflichtet sich Winston AI zur vollständigen Offenlegung seiner Forschungsergebnisse über die Trefferquote. Wir haben einen umfassenden Datensatz von 10.000 Texten entwickelt, darunter 5.000 menschliche Texte und 5.000 von der KI generierte Texte, die mit den bekanntesten Large Language Models, einschließlich ChatGPT (GPT 3.5 Turbo, GPT 4, GPT 4 Turbo), Claude V1 und Claude V2, erstellt wurden. Der Inhalt dieser Daten war ebenfalls vielfältig und umfasste Nachrichtenartikel, Blogs, Essays, Gedichte, Dissertationen und mehr. Dieser Datensatz, der von menschlichen Experten rigoros validiert wurde, stellt einen neuen Präzedenzfall für die Offenheit in diesem Bereich dar.
Winston AI hat einen mutigen Schritt unternommen, um einen neuen Standard für Offenheit zu setzen. Von den unzähligen verfügbaren KI-Schrifterkennungsprogrammen hat bisher noch keines Angaben zu seiner Trefferquote gemacht. Die Geheimniskrämerei, die diese wichtigen Statistiken umgibt, ist wenig vertrauenserweckend für Benutzer, die eine zuverlässige Lösung zur Erkennung von Inhalten suchen.
Wir stellen daher einen umfangreichen Datensatz von 10.000 Texten vor, auf den wir im Folgenden näher eingehen.
Wir sind zuversichtlich, dass diese Veröffentlichung dazu beitragen wird, das Vertrauen unserer Nutzer zu stärken, während unser Team daran arbeitet, ein wachsendes Problem bei der Erkennung von KI-generierten Inhalten zu lösen.
Materialien und Methodik
Eines der Schlüsselelemente bei der Entwicklung eines präzisen Tools ist die Qualität der Daten. Hier liegt unserer Meinung nach der Kern der Herausforderung bei der Entwicklung einer präzisen Lösung. Der Datensatz, der zur Prüfung unserer Genauigkeit verwendet wird, ist „zufällig“, und keine der zu Testzwecken verwendeten Daten wurde überhaupt für das Training unseres Modells verwendet.
Unser Team erstellte einen umfangreichen Datensatz mit 5.000 zufällig ausgewählten, von Menschen geschriebenen Texten verschiedener Genres, darunter:
- Aufsätze & Dissertationen
- Fan-Fiction
- Reden
- Medizinische Papiere
- Filmkritiken
- Blogs / Nachrichtenartikel
- Gedichte
- Rezepte
- Stapelüberlauf
- Wikipedia
Es ist auch wichtig zu erkennen, dass die Vertrauenswürdigkeit von Inhalten, die nach 2021 erstellt werden, weitgehend fraglich ist. Aufgrund der potenziellen Verbesserung durch KI stammen die herangezogenen Inhalte aus der Zeit vor 2021. Alle verwendeten Texte enthielten mindestens 600 Zeichen, da kürzere Textlängen nicht zuverlässig als KI oder Mensch klassifiziert werden können. Das ist auch der Grund, warum unser KI-Detektor keine Bewertungen für Texte mit weniger als 600 Zeichen liefert.
Verfahren zur Erfassung schriftlicher Daten von Menschen
Um die Qualität des Datensatzes zu gewährleisten, hat sich unser Team bemüht, die Verwendung bereits vorhandener Daten aus externen Quellen zu vermeiden. Unsere Beobachtung war, dass die überwiegende Mehrheit der populären großen Datensätze, die online verfügbar sind (The Pile, Common Crawl usw.), und die Benchmark-Datensätze der Wettbewerber nicht „sauber“ waren. Bei näherer Betrachtung dieser großen Datensätze stellte unser Team fest, dass sie mehrere Texte enthielten, die nicht korrekt formatiert waren, die nicht lesbar waren, die mehrere nicht erkennbare Zeichen enthielten oder Texte in verschiedenen Sprachen, die fremde Zeichen enthielten (Syrillisch, Chinesisch, Hangu, Arabisch).
Wir haben auch sichergestellt, dass alle Daten, die wir für die Schulung verwendet haben, aus der Zeit vor 2021 stammen. Es gibt Berichte, dass mehrere seriöse Quellen, darunter auch Wikipedia, mit KI-generierten Beiträgen aktualisiert worden sind 1 .
Wir stellten sicher, dass alle Inhalte in unserem Datensatz korrekt kodiert waren (UTF-8), um Missverständnisse bei den in das Modell eingespeisten Daten zu vermeiden.
Jede einzelne Dateneingabe wurde überprüft, richtig kodiert, lesbar und enthielt keine fremden Sprachen und Zeichen.
Verfahren zur Erfassung von AI-generierten/synthetischen Daten
Parallel dazu haben wir einen KI-generierten Datensatz mit 5.000 Texten erstellt, die mit den meisten wichtigen KI-Schreibwerkzeugen erzeugt wurden, die zum Zeitpunkt des Tests über eine öffentlich verfügbare API verfügten, darunter GPT 3.5 Turbo, GPT 4, GPT 4 Turbo, Claude V1 und Claude V2.
Es gibt einige Schlüsselelemente, die sicherstellen, dass unsere Trefferquote gültig ist:
- Für jeden LLM wurden verschiedene Aufforderungen und Anweisungen in mehreren Feldern verwendet, um die Ausgaben zu variieren und den von Menschen geschriebenen Inhalt widerzuspiegeln.
- Es wurde eine Vielzahl von Temperatureinstellungen verwendet, um ein breites Spektrum an synthetischen Daten zu erzeugen.
Schließlich musste unser Team jeden Text, der in unseren Datensatz von 10.000 Texten aufgenommen wurde, überprüfen, um sicherzustellen, dass der Inhalt akzeptabel war. Den vollständigen Datensatz, der für unsere jüngste Bewertung der Trefferquote verwendet wurde, finden Sie hier. Zu Ihrer Erleichterung ist er sowohl im .csv- als auch im .jsonl-Format verfügbar.
Was versteht Winston AI unter Synthetischem Schreiben? (und was ist die menschliche Schrift?)
Es gibt mehrere Anwendungsfälle, mit denen wir konfrontiert wurden. Dies ist, was Winston AI als KI-Inhalte betrachtet und was nicht:
- Von Menschen geschrieben und bearbeitet: Menschlicher Inhalt
- Von Menschen geschrieben und mit Grammarly (Legacy) korrigiert: Menschlicher Inhalt
- KI-Forschung und -Entwurf, Human written: Menschlicher Inhalt
- Von der KI generierte Gliederung, von einem Menschen geschrieben und dann von der KI neu geschrieben: KI-Inhalt
- Von Menschen geschrieben und mit einem KI-Schreibprogramm umgeschrieben: KI-Inhalt
- Mit KI erstellt und von einem Menschen bearbeitet: KI-Inhalt
- Mit KI generiert und von einem „AI Humanizer“ umgeschrieben: KI-Inhalt
- Erzeugt oder bearbeitet mit Grammarly Go: KI-Inhalt
- Generiert mit KI ohne jegliche menschliche Anpassungen: KI-Inhalt
Für detailliertere Informationen darüber, wie Winston AI Inhalte bewertet, die mit Grammarly überarbeitet wurden, empfehlen wir unseren Artikel zu diesem speziellen Thema.
Bewertungsmetriken
Damit eine Bewertung als erfolgreich gilt, muss unsere Software mit einer Wahrscheinlichkeit von mehr als 50 % feststellen, ob der Inhalt von Menschen geschrieben oder von einer KI generiert wurde. Zur Verdeutlichung: Wenn ein Text von Menschenhand erstellt wurde, muss er zu mindestens 51 % von Menschenhand bewertet werden, damit die Bewertung als korrekt gilt. Eine Punktzahl von 50 % oder weniger würde eine nicht erfolgreiche Bewertung bedeuten. Umgekehrt ist für eine erfolgreiche Bewertung von KI-generierten Inhalten eine menschliche Bewertung von 49 % oder weniger erforderlich. Im Wesentlichen hängt die Bewertung von einer Mehrheitswahrscheinlichkeit ab – über 50 % für von Menschen geschriebene Inhalte und unter 50 % für KI-generiertes Material.
Es gibt also 3 Bewertungen, die unsere Organisation durchführt:
- KI-Erkennungsgenauigkeit: Zeigt unsere Fähigkeit an, KI-generierte Inhalte mit einem probabilistischen Prozentsatz zu bewerten.
- Genauigkeit der menschlichen Erkennung: Zeigt unsere Fähigkeit an, von Menschen erstellte Inhalte mit einem probabilistischen Prozentsatz zu bewerten.
- Gesamtbewertung: Unser gewichteter Durchschnitt bei der Ermittlung von KI-generierten Inhalten und menschlichen Inhalten.
Ergebnisse und Fehlerspanne
Unsere Genauigkeitswerte wurden ermittelt, indem wir unseren Hauptdatensatz von 10.000 Texten (siehe oben) durch unser proprietäres KI-Erkennungsmodell laufen ließen.
Was die Genauigkeit der KI-Erkennung betrifft, so konnte die Lösung von Winston AI KI-generierte Inhalte mit einer Genauigkeit von 99,98 % erkennen.
Was die Erkennungsgenauigkeit betrifft, so haben unsere umfangreichen Tests ergeben, dass Winston AI von Menschen generierten Text mit einer Genauigkeit von 99,50 % erkennen kann .
Insgesamt bedeutet dies, dass unser gewichteter Durchschnitt (Gesamtnote) 99,74 % beträgt. Bei einem so großen Stichprobenumfang ist unsere Fehlerspanne mit nur 0,0998 % sehr gering.
| AI-Genauigkeit | AI MoE | AI F1 | Menschliche Akkuratesse | Menschliches MoE | Mensch F1 | Gesamtgenauigkeit | Gesamtes MoE |
|---|---|---|---|---|---|---|---|
| 99.98 | 0.0392 | 0.997 | 99.5 | 0.196 | 0.997 | 99.74 | 0.0998 |
Wichtigste LLM-Genauigkeitsergebnisse
| GPT 3.5 Turbo | GPT 4 | GPT 4 Turbo | Claude 1 | Claude 2 |
|---|---|---|---|---|
| 100.00% | 100.00% | 100.00% | 99.63% | 100.00% |
Die obige Tabelle gibt einen Überblick über unsere Genauigkeit bei der Erkennung bestimmter populärer großer Sprachmodelle.
Genauigkeit der von Menschen geschriebenen Inhalte
| Fan-Fiction | Medizinische Papiere | Gedichte | Filmkritiken | Nachrichten / Blog | Reden | Wikipedia | Stapelüberlauf | Rezepte | Aufsätze / Dissertationen | |
|---|---|---|---|---|---|---|---|---|---|---|
| 99.09% | 100.00% | 98.85% | 100.00% | 99.56% | 100.00% | 100.00% | 99.15% | 98.05% | 100.00% | 100.00% |
Die obige Tabelle gibt einen Überblick über unsere Genauigkeit bei der Erkennung bestimmter Arten von von Menschen geschriebenen Inhalten (Human Detection).
Vergleich der Versionen
| Version | KI-Genauigkeit | Menschliche Genauigkeit | Gesamtnote |
|---|---|---|---|
| 3.0 „Luka“ | 99.98% | 99.5% | 99.74% |
| 2.0 | 99.6% | 98.4% | 99% |
Die obige Tabelle gibt einen Überblick über die Entwicklung unserer Genauigkeitswerte seit der letzten großen Aktualisierung.
Verwirrungsmatrix
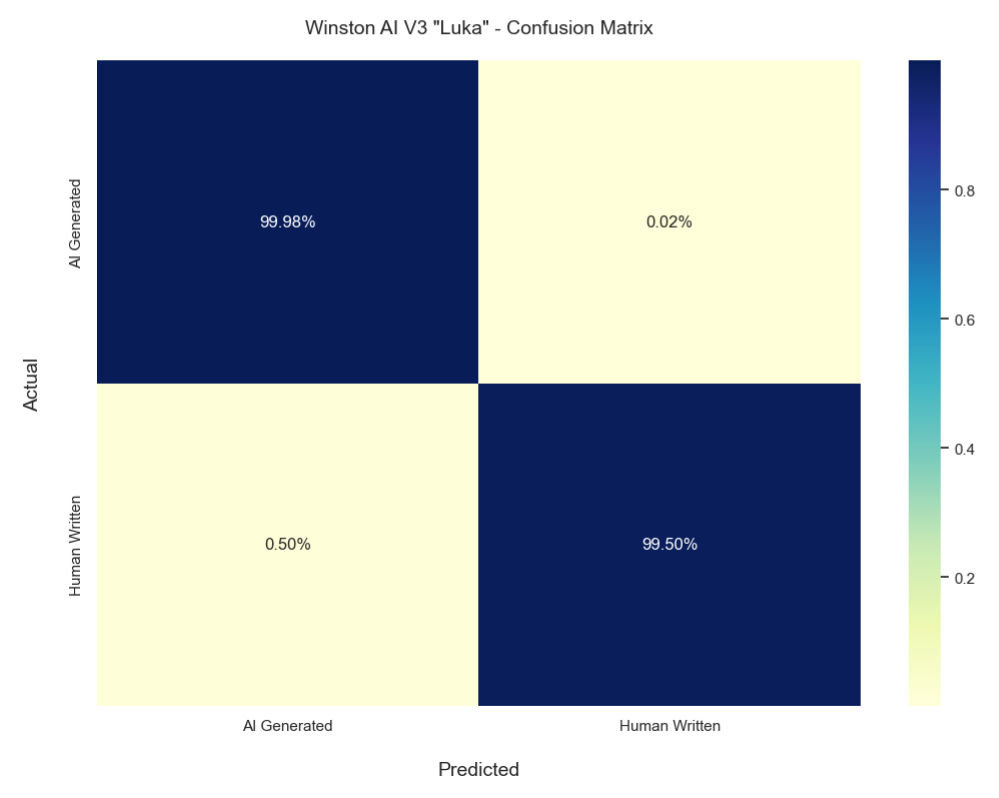
Das obige Diagramm zeigt die Konfusionsmatrix unseres neuesten KI-Erkennungsmodells.
Schlussfolgerung
Winston AI hat beispiellose Schritte unternommen, um Transparenz in das wichtige, aber undurchsichtige Thema der Genauigkeitsraten bei der Erkennung von KI-Inhalten zu bringen. Durch die Veröffentlichung aller Details und Daten, die hinter unserer branchenführenden Trefferquote von 99,74 % stehen, hoffen wir, eine neue Kultur der Offenheit und Integrität zu schaffen. Die Benutzer verdienen es, die wahren Fähigkeiten der von ihnen verwendeten Werkzeuge zu kennen. Mit der zunehmenden Verbreitung von KI-Inhalten wächst der Bedarf an zuverlässigen Tools zur Erkennung synthetischer Inhalte. Wir sind bestrebt, Organisationen und Einzelpersonen bei der Wahrung ihrer Integrität zu helfen. Wenn unsere Transparenz ein Vorbild für andere ist, werden wir einen Schritt in Richtung einer Zukunft gemacht haben, in der die Nutzer volles Vertrauen in die von KI-Erkennungslösungen versprochenen Genauigkeitsraten haben können.
Referenzen
FAQ
Mit der zunehmenden Verbreitung von KI sind zuverlässige Werkzeuge zur Erkennung synthetischer Inhalte von entscheidender Bedeutung. Aber nicht alle Detektoren sind gleich. Undurchsichtige Versprechungen über die Genauigkeit tragen wenig dazu bei, das Vertrauen der Nutzer zu stärken. Mit der Veröffentlichung der vollständigen Daten zu unserer branchenführenden Quote von 99,74 % hoffen wir, Offenheit und Vertrauen zu schaffen.
Sorgfältige Kuratierung. 10.000 Texte aus verschiedenen Genres. 5.000 Menschen, 5.000 KI. Erzeugt mit vielen wichtigen KI-Tools, darunter ChatGPT (GPT 3.5 Turbo, GPT 4 und GPT 4 Turbo), Claude 1 und Claude 2. Jedes Stück wird von Menschen geprüft. Ein Niveau an Qualität und Transparenz, das seinesgleichen sucht.
Klare, strenge Benchmarks. AI-Texte wurden zu 99,98 % korrekt als AI identifiziert. Menschliche Texte werden zu 99,50 % korrekt als menschlich identifiziert. Ein transparenter gewichteter Durchschnitt von 99,74 %. Die Fehlermarge beträgt lediglich 0,0998 %. Der Beweis liegt in den Daten.
Vertrauen durch Transparenz. Die Benutzer verdienen es, die wahren Fähigkeiten eines Tools zu kennen. Undurchsichtige Behauptungen wecken Zweifel. Mit der Veröffentlichung der vollständigen Fakten wollen wir einen neuen Standard für die Integrität bei der KI-Erkennung setzen.
Genau hier. Wir glauben, dass Transparenz die Grundlage für das Vertrauen zwischen einem Unternehmen und seinen Nutzern ist. Informieren Sie sich über die Daten, die unserer branchenführenden Genauigkeit zugrunde liegen.
@misc{Lavergne_2023, title={A deep dive into our best in class accuracy rate}, url={https://gowinston.ai/setting-new-standards-in-ai-content-detection/}, journal={Winston AI}, publisher={Winston AI}, author={Lavergne, Thierry}, year={2023}, month={Dec}}