AI is moving at an incredibly fast pace. As AI-generated content creation proliferates, so does the necessity for robust mechanisms to discern between synthetic and human writing. Consequently, we’ve witnessed the rise of AI content detectors.
It has become obvious that not all content detectors are created equal. A profusion of solutions has flooded the market, each touting its own self-proclaimed accuracy rates. These statistics, while promising on the surface, often lack the transparency and scrutiny required to inspire true confidence in their efficacy.
Our objective is to remain at the forefront of helping institutions and enterprises maintain integrity and the best way to achieve that is to offer the highest accuracy rate in the industry.
This article embarks on a deep dive of Winston AI’s newest english AI detection model and third major release (V3.0), codenamed “Luka”.
Our objective is to dispel the opacity surrounding accuracy rates in content detection. Our dedication to transparency is a testament to our belief that users deserve more than just promises of effectiveness—they merit a tool backed by transparent data.
A new standard of transparency for AI Detection
Unlike most other AI content detection tools, Winston AI commits to full disclosure of its accuracy rate research. We have developed a comprehensive dataset of 10,000 texts, including 5,000 human texts and 5,000 AI generated texts generated with most known Large Language Models, including ChatGPT (GPT 3.5 Turbo, GPT 4, GPT 4 Turbo), Claude V1 and Claude V2. The content in this data was also varied, including News articles, blogs, essays, poetry, theses and more. This dataset, rigorously validated by human experts, sets a new precedent in openness within the field.
Winston AI has taken a bold step towards establishing a new standard of openness. Among the myriad of AI writing detection tools available, none have thus far divulged any details of their accuracy rates. The secrecy that surrounds these crucial statistics does little to inspire confidence or instill faith in users seeking a reliable content detection solution.
We therefore present a comprehensive dataset consisting of 10,000 texts, of which we will provide details below.
We trust this release will help us build trust with our users as our team works to solve a growing problem in detecting AI generated content.
Materials and methodology
One of the key elements that went into building an accurate tool is the quality of the data. This is where we believe lies the core of the challenge in building an accurate solution. The dataset used to test our accuracy is “random” and none of the data used for testing purposes was used for training our model in the first place.
Our team built an extensive dataset containing 5,000 randomly selected human written texts of diverse genres, including:
- Essays & Theses
- Fan fiction
- Speeches
- Medical papers
- Movie reviews
- Blogs / News articles
- Poems
- Recipes
- Stack Overflow
- Wikipedia
It’s also crucial to acknowledge that the trustworthiness of content created after 2021 is largely questionable. Due to the potential enhancement by AI, the content relied upon was sourced from before 2021. All text used contained a minimum of 600 characters as shorter text lengths cannot be reliably classified as AI or Human. This is also why our AI Detector doesn’t provide assessments on texts that are less than 600 characters.
Process used to gather human written data
Our team went to lengths to avoid using pre-existing data from external sources to ensure the quality of the dataset. Our observation was that the vast majority of popular large datasets available online (The Pile, Common Crawl, etc.), and benchmark datasets from competitors were not “clean”. Upon closer inspection of these large datasets, our team found that they contained several texts that were not formatted correctly, that were unreadable, that contained several unrecognizable characters, or had texts in various languages containing foreign characters (Syrillic, Chinese, Hangu, Arabic).
We also ensured that any data we used for training was dated pre-2021. There have been reports that several reputable sources, including Wikipedia, have been updated with contributions that were AI generated1.
We made certain that all of the content in our dataset was correctly encoded (UTF-8), to avoid any occurrences of misunderstanding of the data fed to the model.
Every single data entry was verified, encoded properly, readable, and didn’t contain any foreign languages and characters.
Process used to gather AI generated/Synthetic data
In parallel, we built an AI generated dataset of 5,000 texts generated with most major AI writing tools with a publicly available API at the time of testing, including GPT 3.5 Turbo, GPT 4, GPT 4 Turbo, Claude V1 and Claude V2.
A few key elements to ensuring our accuracy rate is valid:
- For each LLM, various prompts and instructions in multiple fields were used to vary the outputs and mirror the human written content.
- A multitude of temperature settings were used to generate a wide range of synthetic data styles.
Finally, our team had to vet every piece of text that went into our dataset of 10,000 to ensure the content was acceptable. You can find the complete dataset used for our most recent accuracy rate assessment here. For your convenience, it is available in both .csv and .jsonl formats.
What does Winston AI consider as Synthetic Writing? (and what is human writing?)
There are several use cases that we’ve been faced with. This is what Winston AI believes is AI content and what isn’t:
- Human written and edited: Human content
- Human written and corrections made with Grammarly (legacy): Human content
- AI research and outline, Human written: Human content
- Outline generated by AI, written by a human, and then re-written by AI: AI content
- Human written and rewritten with an AI writing tool: AI content
- Generated with AI and edited by a human: AI content
- Generated with AI and rewritten by a “AI Humanizer”: AI content
- Generated or edited with Grammarly Go: AI content
- Generated with AI without any humans adjustments: AI content
For more detailed information on how Winston AI assesses content that has been revised with Grammarly, we recommend our article on this specific topic.
Evaluation metrics
For an evaluation to be deemed successful, our software must determine the likelihood of content being human-written or AI-generated with a probability exceeding 50%. To clarify, if a piece of text is human-generated, it needs a human score of 51% or higher for the assessment to be considered accurate. A score of 50% or less would indicate an unsuccessful evaluation. Conversely, for AI-generated content, a successful assessment requires a human score of 49% or less. Essentially, the evaluation hinges on a majority probability — above 50% for human-written content and below 50% for AI-generated material.
There are therefore 3 evaluations that our organization conducts:
- AI detection accuracy score: Outlines our ability to evaluate AI generated content with a probabilistic percentage.
- Human detection accuracy score: Outlines our ability to evaluate human generated content with a probabilistic percentage.
- Overall score: Our weighted average in determining AI generated content and Human content.
Results and error margin
Our accuracy scores were obtained by running our main dataset of 10,000 texts provided above through our proprietary AI detection model.
For our AI detection accuracy score, Winston AI’s solution was able to detect AI generated content with an accuracy of 99.98%.
As for our Human detection accuracy score, our extensive tests revealed that Winston AI can identify human generated text with an accuracy rate of 99.50%.
Overall, this means that our weighted average (overall score) is 99.74%. With such a large sample size, our error margin is ever so small at a mere 0.0998%.
| AI Accuracy | AI MoE | AI F1 | Human Accuracy | Human MoE | Human F1 | Overall Accuracy | Overall MoE |
|---|---|---|---|---|---|---|---|
| 99.98 | 0.0392 | 0.997 | 99.5 | 0.196 | 0.997 | 99.74 | 0.0998 |
Major LLM accuracy scores
| GPT 3.5 Turbo | GPT 4 | GPT 4 Turbo | Claude 1 | Claude 2 |
|---|---|---|---|---|
| 100.00% | 100.00% | 100.00% | 99.63% | 100.00% |
The above table outlines our accuracy in detecting specific popular Large Language Models.
Human written content accuracy scores
| Fan Fiction | Medical Papers | Poems | Movie Reviews | News / Blog | Speeches | Wikipedia | Stack Overflow | Recipes | Essays / Theses | |
|---|---|---|---|---|---|---|---|---|---|---|
| 99.09% | 100.00% | 98.85% | 100.00% | 99.56% | 100.00% | 100.00% | 99.15% | 98.05% | 100.00% | 100.00% |
The above table outlines our accuracy in detecting specific types of Human Written Content (Human Detection).
Version comparison
| Version | AI accuracy | Human accuracy | Overall score |
|---|---|---|---|
| 3.0 “Luka” | 99.98% | 99.5% | 99.74% |
| 2.0 | 99.6% | 98.4% | 99% |
The above table outlines the progression of our accuracy scores since our last major update.
Confusion matrix
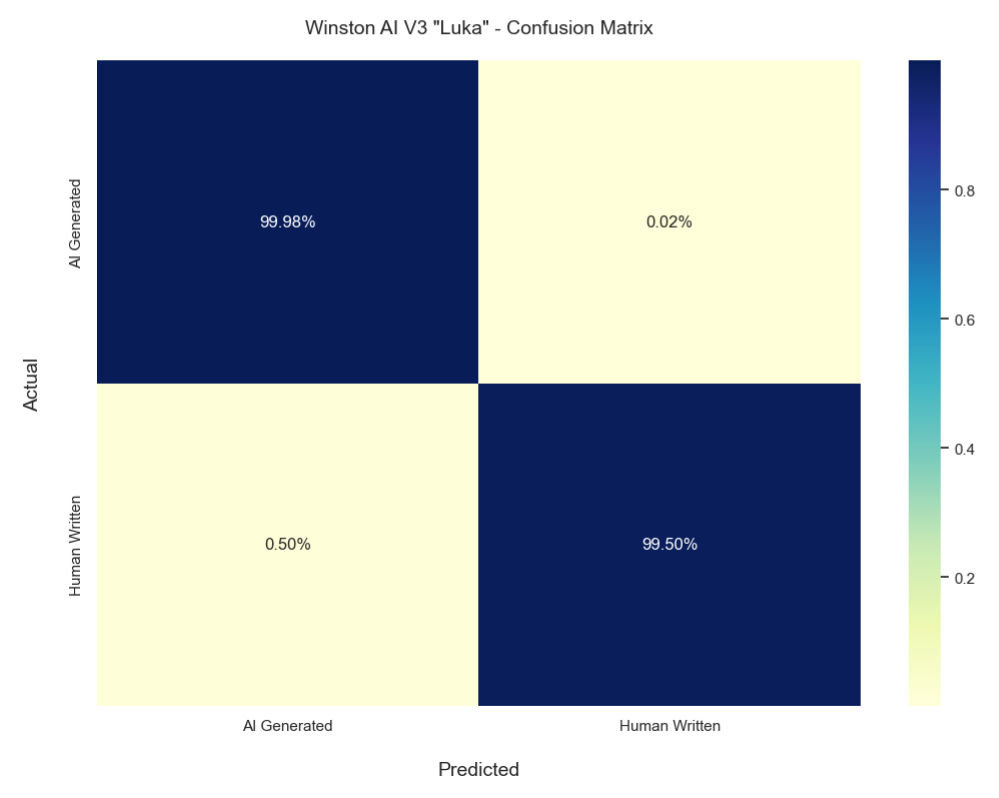
The above graph shows the Confusion Matrix of our latest AI detection model.
Conclusion
Winston AI has taken unprecedented steps to bring transparency to the crucial but opaque issue of accuracy rates in AI content detection. By releasing the full details and data behind our industry-leading 99.74% accuracy rate, we hope to inspire a new culture of openness and integrity. Users deserve to know the true capabilities of the tools they use. As AI content proliferates, the need for reliable tools to discern synthetic content only grows. We are committed to remaining at the cutting edge in helping organizations and individuals uphold integrity. If our transparency provides a template for others to follow, we will have succeeded in taking a step towards a future in which users can place full confidence in the accuracy rates promised by AI detection solutions.
References
- Claire Woodcock. AI Is Tearing Wikipedia Apart. Vice.com, 2023. https://www.vice.com/en/article/v7bdba/ai-is-tearing-wikipedia-apart. Accessed December 5th 2023. ↩︎
FAQ
As AI proliferates, reliable tools to detect synthetic content are crucial. But not all detectors are created equal. Opaque promises of accuracy do little to build user trust. By releasing full data on our industry-leading 99.74% rate, we hope to inspire openness and confidence.
Meticulous curation. 10,000 texts across diverse genres. 5,000 human, 5,000 AI. Generated using many major AI tools including ChatGPT (GPT 3.5 Turbo, GPT 4 and GPT 4 Turbo), Claude 1 and Claude 2. Every piece is vetted by humans. A level of quality and transparency with no precedent.
Clear, rigorous benchmarks. AI texts correctly identified as AI at 99.98%. Human texts correctly identified as human at 99.50%. A transparent weighted average of 99.74%. A mere 0.0998% margin of error. The proof is in the data.
Trust through transparency. Users deserve to know a tool’s true capabilities. Opaque claims inspire doubt. By releasing the full facts, we aim to set a new standard of integrity in AI detection.
Right here. We believe transparency is the foundation of trust between a company and its users. Please explore the data that powers our industry-leading accuracy.
@misc{Lavergne_2023, title={A deep dive into our best in class accuracy rate}, url={https://gowinston.ai/setting-new-standards-in-ai-content-detection/}, journal={Winston AI}, publisher={Winston AI}, author={Lavergne, Thierry}, year={2023}, month={Dec}}