L’IA évolue à un rythme incroyablement rapide. La prolifération de la création de contenu généré par l’IA s’accompagne de la nécessité de mettre en place des mécanismes robustes permettant de distinguer les écrits synthétiques des écrits humains. C’est pourquoi nous avons assisté à l’essor des détecteurs de contenu d’IA.
Il est devenu évident que tous les détecteurs de contenu ne se valent pas. Une profusion de solutions a inondé le marché, chacune vantant ses propres taux de précision. Ces statistiques, bien que prometteuses en apparence, manquent souvent de la transparence et de l’examen minutieux nécessaires pour inspirer une véritable confiance dans leur efficacité.
Notre objectif est de rester à l’avant-garde en aidant les institutions et les entreprises à maintenir leur intégrité, et le meilleur moyen d’y parvenir est d’offrir le taux de précision le plus élevé du secteur.
Cet article propose une analyse approfondie du tout nouveau modèle de détection de Winston AI et de sa troisième version majeure (V3.0), dont le nom de code est « Luka ».
Notre objectif est de dissiper l’opacité qui entoure les taux de précision dans la détection de contenu. Notre volonté de transparence témoigne de notre conviction que les utilisateurs méritent plus que de simples promesses d’efficacité – ils méritent un outil étayé par des données transparentes.
Une nouvelle norme de transparence pour la détection de l’IA
Contrairement à la plupart des autres outils de détection de contenu par l’IA, Winston AI s’engage à divulguer l’intégralité de ses recherches sur le taux de précision. Nous avons développé un ensemble de données complet de 10 000 textes, dont 5 000 textes humains et 5 000 textes générés par l’IA à l’aide des modèles de langage les plus connus, notamment ChatGPT (GPT 3.5 Turbo, GPT 4, GPT 4 Turbo), Claude V1 et Claude V2. Le contenu de ces données était également varié : articles d’actualité, blogs, essais, poésie, thèses, etc. Cet ensemble de données, rigoureusement validé par des experts humains, établit un nouveau précédent en matière d’ouverture dans le domaine.
Winston AI a pris une mesure audacieuse pour établir une nouvelle norme d’ouverture. Parmi la myriade d’outils de détection d’écriture par l’IA disponibles, aucun n’a jusqu’à présent divulgué de détails sur leurs taux de précision. Le secret qui entoure ces statistiques cruciales ne contribue guère à inspirer confiance aux utilisateurs à la recherche d’une solution de détection de contenu fiable.
C’est pourquoi nous présentons un ensemble de données complet composé de 10 000 textes, dont nous donnons les détails ci-dessous.
Nous sommes convaincus que cette publication nous aidera à instaurer un climat de confiance avec nos utilisateurs, alors que notre équipe s’efforce de résoudre le problème croissant de la détection des contenus générés par l’IA.
Documentation et méthodologie
L’un des éléments clés de la construction d’un outil précis est la qualité des données. Nous pensons que c’est là que réside le cœur du défi que représente l’élaboration d’une solution précise. L’ensemble de données utilisé pour tester notre précision est « aléatoire » et aucune des données utilisées à des fins de test n’a été utilisée pour former notre modèle en premier lieu.
Notre équipe a constitué un vaste ensemble de données contenant 5 000 textes écrits par des humains, sélectionnés au hasard et de genres différents :
- Essais et thèses
- Fiction
- Discours
- Articles médicaux
- Critiques de films
- Blogs / Actualités
- Poésie
- Recettes
- Stack Overflow
- Wikipedia
Il est également essentiel de reconnaître que la fiabilité des contenus créés après 2021 est largement sujette à caution. En raison du potentiel d’amélioration de l’IA, le contenu utilisé a été créé avant 2021. Tous les textes utilisés contenaient un minimum de 600 caractères, car les textes plus courts ne peuvent pas être classés de manière fiable comme étant de l’IA ou de l’humain. C’est également la raison pour laquelle notre détecteur d’IA ne fournit pas d’évaluation pour les textes de moins de 600 caractères.
Processus utilisé pour recueillir des données humaines écrites
Notre équipe s’est efforcée d’éviter d’utiliser des données préexistantes provenant de sources externes afin de garantir la qualité de l’ensemble de données. Nous avons constaté que la grande majorité des grands ensembles de données populaires disponibles en ligne (The Pile, Common Crawl, etc.) et les ensembles de données de référence des concurrents n’étaient pas « propres ». En examinant de plus près ces grands ensembles de données, notre équipe a constaté qu’ils contenaient plusieurs textes qui n’étaient pas formatés correctement, qui étaient illisibles, qui contenaient plusieurs caractères non reconnaissables, ou des textes dans diverses langues contenant des caractères étrangers (syrillique, chinois, hangu, arabe).
Nous avons également veillé à ce que les données utilisées pour la formation soient antérieures à 2021. Selon certains rapports, plusieurs sources réputées, dont Wikipédia, ont été mises à jour avec des contributions générées par l’IA1.
Nous nous sommes assurés que tout le contenu de notre ensemble de données était correctement codé (UTF-8), afin d’éviter toute incompréhension des données transmises au modèle.
Chaque entrée de données a été vérifiée, codée correctement, lisible et ne contenant pas de langues ou de caractères étrangers.
Processus utilisé pour recueillir les données générées par l’IA/les données synthétiques
En parallèle, nous avons construit un ensemble de données générées par l’IA de 5 000 textes générés avec la plupart des principaux outils de rédaction d’IA disposant d’une API publiquement disponible au moment du test, y compris GPT 3.5 Turbo, GPT 4, GPT 4 Turbo, Claude V1 et Claude V2.
Quelques éléments clés garantissent la validité de notre taux de précision :
Pour chaque LLM, diverses invites et instructions dans plusieurs champs ont été utilisées pour varier les résultats et refléter le contenu écrit par l’homme.
Une multitude de paramètres de température ont été utilisés pour générer un large éventail de styles de données synthétiques.
Enfin, notre équipe a dû vérifier chaque texte introduit dans notre ensemble de données de 10 000 pour s’assurer que le contenu était acceptable. Vous trouverez ici l’ensemble des données utilisées pour notre dernière évaluation du taux de précision. Pour plus de commodité, il est disponible aux formats .csv et .jsonl.
Qu’est-ce que Winston AI considère comme de l’écriture synthétique ? (et qu’est-ce que l’écriture humaine ?)
Nous avons été confrontés à plusieurs cas d’utilisation. Voici ce que Winston AI considère comme du contenu d’IA et ce qui ne l’est pas :
- Rédigé et édité par des personnes : Contenu humain
- Rédigé par un humain et corrections faites avec Grammarly (legacy) : Contenu humain
- Recherche et ébauche par l’IA, rédaction par l’homme : Contenu humain
- Schéma généré par l’IA, rédigé par un humain, puis réécrit par l’IA : contenu de l’IA
- Écrit par un humain et réécrit avec un outil de rédaction d’IA : Contenu IA
- Généré par l’IA et édité par un humain : Contenu d’IA
- Généré par l’IA et réécrit par un « AI Humanizer » : Contenu d’IA
- Généré ou édité avec Grammarly Go : Contenu AI
- Généré par l’IA sans aucun ajustement humain : Contenu AI
Pour des informations plus détaillées sur la façon dont Winston AI évalue le contenu qui a été révisé avec Grammarly, nous vous recommandons notre article sur ce sujet spécifique.
Critères d’évaluation
Pour qu’une évaluation soit considérée comme réussie, notre logiciel doit déterminer la probabilité que le contenu soit écrit par un humain ou généré par une IA avec une probabilité supérieure à 50 %. En d’autres termes, si un texte est généré par l’homme, il doit obtenir une note humaine de 51 % ou plus pour que l’évaluation soit considérée comme exacte. Un score de 50 % ou moins indique que l’évaluation n’a pas abouti. Inversement, pour un contenu généré par l’IA, une évaluation réussie nécessite une note humaine de 49 % ou moins. En fait, l’évaluation repose sur une probabilité majoritaire – supérieure à 50 % pour les contenus rédigés par l’homme et inférieure à 50 % pour les contenus générés par l’IA.
Notre organisation procède donc à trois évaluations :
- Score de précision de la détection de l’IA : Indique notre capacité à évaluer le contenu généré par l’IA à l’aide d’un pourcentage probabiliste.
- Score de précision de la détection humaine : Indique notre capacité à évaluer le contenu généré par l’homme avec un pourcentage probabiliste.
- Note globale : Notre moyenne pondérée pour déterminer le contenu généré par l’IA et le contenu humain.
Résultats et marge d’erreur
Nos scores de précision ont été obtenus en soumettant notre ensemble de données principal de 10 000 textes à notre modèle propriétaire de détection de l’IA.
Pour notre score de précision de détection de l’IA, la solution de Winston AI a été capable de détecter le contenu généré par l’IA avec une précision de 99,98%.
Quant à notre score de précision de détection humaine, nos tests approfondis ont révélé que Winston AI peut identifier les textes générés par l’homme avec un taux de précision de 99,50 %.
Dans l’ensemble, cela signifie que notre moyenne pondérée (score global) est de 99,74 %. Avec un échantillon aussi large, notre marge d’erreur est très faible, puisqu’elle n’est que de 0,0998 %.
| AI Accuracy | AI MoE | AI F1 | Human Accuracy | Human MoE | Human F1 | Overall Accuracy | Overall MoE |
|---|---|---|---|---|---|---|---|
| 99.98 | 0.0392 | 0.997 | 99.5 | 0.196 | 0.997 | 99.74 | 0.0998 |
Scores de précision pour les principaux LLM
| GPT 3.5 Turbo | GPT 4 | GPT 4 Turbo | Claude 1 | Claude 2 |
|---|---|---|---|---|
| 100.00% | 100.00% | 100.00% | 99.63% | 100.00% |
Le tableau ci-dessus indique notre précision dans la détection de modèles d’IA plus connus.
Score de précision des contenus rédigés par des humains
| Fan Fiction | Medical Papers | Poems | Movie Reviews | News / Blog | Speeches | Wikipedia | Stack Overflow | Recipes | Essays / Theses | |
|---|---|---|---|---|---|---|---|---|---|---|
| 99.09% | 100.00% | 98.85% | 100.00% | 99.56% | 100.00% | 100.00% | 99.15% | 98.05% | 100.00% | 100.00% |
Le tableau ci-dessus indique notre précision dans la détection de types spécifiques de contenu écrit par des humains (détection humaine).
Comparaison des versions
| Version | AI accuracy | Human accuracy | Overall score |
|---|---|---|---|
| 3.0 « Luka » | 99.98% | 99.5% | 99.74% |
| 2.0 | 99.6% | 98.4% | 99% |
Le tableau ci-dessus présente la progression de nos scores de précision depuis notre dernière mise à jour majeure.
Matrice de confusion
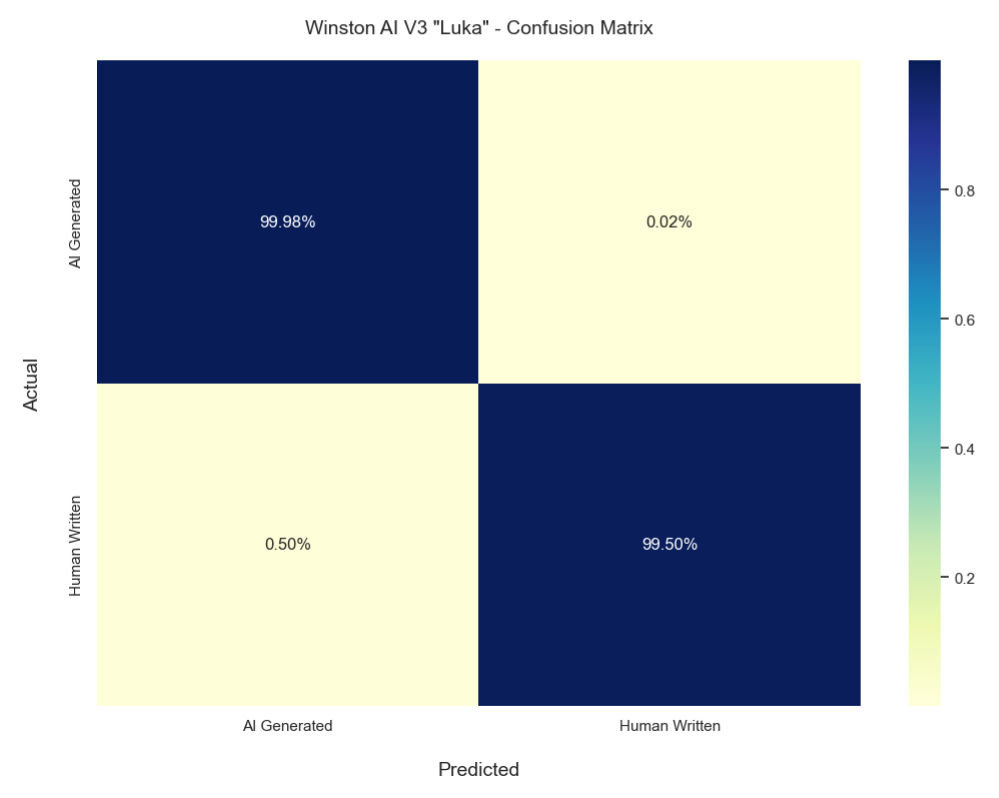
Le graphique ci-dessus montre la matrice de confusion de notre dernier modèle de détection de l’IA.
Conclusion
Winston AI a pris des mesures sans précédent pour apporter de la transparence à la question cruciale mais opaque des taux de précision dans la détection de contenu par l’IA. En publiant tous les détails et les données qui sous-tendent notre taux de précision de 99,74 %, le plus élevé de l’industrie, nous espérons inspirer une nouvelle culture d’ouverture et d’intégrité. Les utilisateurs méritent de connaître les véritables capacités des outils qu’ils utilisent. Avec la prolifération des contenus d’IA, le besoin d’outils fiables pour discerner les contenus synthétiques ne fait que croître. Nous nous engageons à rester à la pointe du progrès en aidant les organisations et les individus à respecter l’intégrité. Si notre transparence sert de modèle à d’autres, nous aurons réussi à faire un pas vers un avenir où les utilisateurs pourront faire pleinement confiance aux taux de précision promis par les solutions de détection de l’IA.
References
FAQ
Avec la prolifération de l’IA, il est essentiel de disposer d’outils fiables pour détecter les contenus synthétiques. Mais tous les détecteurs ne se valent pas. Les promesses opaques de précision ne contribuent guère à renforcer la confiance des utilisateurs. En publiant des données complètes sur notre taux de 99,74 %, le leader du domaine, nous espérons inspirer l’ouverture et la confiance.
Une conservation méticuleuse. 10 000 textes de genres différents. 5 000 humains, 5 000 IA. Générés à l’aide de plusieurs outils d’IA majeurs, notamment ChatGPT (GPT 3.5 Turbo, GPT 4 et GPT 4 Turbo), Claude 1 et Claude 2. Chaque pièce est vérifiée par des humains. Un niveau de qualité et de transparence sans précédent.
Des critères de référence clairs et rigoureux. Textes AI correctement identifiés comme AI à 99,98 %. Textes humains correctement identifiés comme humains à 99,50 %. Une moyenne pondérée transparente de 99,74 %. Une marge d’erreur de seulement 0,0998 %. La preuve est dans les données.
La confiance par la transparence. Les utilisateurs méritent de connaître les véritables capacités d’un outil. Les affirmations opaques inspirent le doute. En publiant tous les détails, nous souhaitons établir une nouvelle norme d’intégrité en matière de détection de l’IA.
Ici même. Nous pensons que la transparence est le fondement de la confiance entre une entreprise et ses utilisateurs. Nous vous invitons à découvrir les données qui nous permettent d’atteindre une précision inégalée dans le secteur.
@misc{Lavergne_2023, title={A deep dive into our best in class accuracy rate}, url={https://gowinston.ai/setting-new-standards-in-ai-content-detection/}, journal={Winston AI}, publisher={Winston AI}, author={Lavergne, Thierry}, year={2023}, month={Dec}}