La IA avanza a un ritmo increíblemente rápido. A medida que prolifera la creación de contenidos generados por IA, también lo hace la necesidad de mecanismos sólidos para discernir entre la escritura sintética y la humana. En consecuencia, hemos asistido al auge de los detectores de contenidos por IA.
Es evidente que no todos los detectores de contenido son iguales. Una profusión de soluciones ha inundado el mercado, cada una de ellas pregonando sus propios índices de precisión autoproclamados. Estas estadísticas, aunque prometedoras en apariencia, carecen a menudo de la transparencia y el escrutinio necesarios para inspirar verdadera confianza en su eficacia.
Nuestro objetivo es mantenernos a la vanguardia de la ayuda a instituciones y empresas para mantener la integridad, y la mejor forma de conseguirlo es ofrecer el mayor índice de precisión del sector.
Este artículo profundiza en el nuevo modelo de detección de IA inglesa de Winston AI y en su tercera versión principal (V3.0), cuyo nombre en clave es «Luka».
Nuestro objetivo es disipar la opacidad que rodea a los índices de precisión en la detección de contenidos. Nuestra dedicación a la transparencia es una prueba de nuestra convicción de que los usuarios merecen algo más que promesas de eficacia: merecen una herramienta respaldada por datos transparentes.
Un nuevo estándar de transparencia para la detección de IA
A diferencia de la mayoría de las herramientas de detección de contenidos por IA, Winston AI se compromete a divulgar íntegramente su investigación sobre el índice de precisión. Hemos desarrollado un amplio conjunto de datos de 10.000 textos, entre los que se incluyen 5.000 textos humanos y 5.000 textos generados por IA con la mayoría de los Large Language Models conocidos, incluidos ChatGPT (GPT 3.5 Turbo, GPT 4, GPT 4 Turbo), Claude V1 y Claude V2. El contenido de estos datos también era variado: artículos de prensa, blogs, ensayos, poesía, tesis, etc. Este conjunto de datos, rigurosamente validado por expertos humanos, sienta un nuevo precedente de apertura en este campo.
Winston AI ha dado un paso valiente hacia el establecimiento de una nueva norma de apertura. Entre la miríada de herramientas de detección de escritura mediante IA disponibles, ninguna ha divulgado hasta ahora detalles sobre sus índices de precisión. El secretismo que rodea a estas estadísticas cruciales no contribuye a inspirar confianza ni a infundir fe en los usuarios que buscan una solución fiable de detección de contenidos.
Por ello, presentamos un amplio conjunto de datos compuesto por 10.000 textos, de los que daremos más detalles a continuación.
Confiamos en que esta versión nos ayude a generar confianza entre nuestros usuarios mientras nuestro equipo trabaja para resolver un problema cada vez mayor en la detección de contenidos generados por IA.
Materiales y metodología
Uno de los elementos clave para crear una herramienta precisa es la calidad de los datos. Aquí es donde creemos que radica el núcleo del reto para construir una solución precisa. El conjunto de datos utilizado para probar nuestra precisión es «aleatorio» y ninguno de los datos utilizados para las pruebas se utilizó para entrenar nuestro modelo en primer lugar.
Nuestro equipo creó un amplio conjunto de datos con 5.000 textos escritos por humanos de diversos géneros seleccionados al azar:
- Ensayos y tesis
- Ficción
- Discursos
- Documentos médicos
- Críticas de películas
- Blogs / Noticias
- Poemas
- Recetas
- Stack Overflow
- Wikipedia
También es crucial reconocer que la fiabilidad de los contenidos creados después de 2021 es en gran medida cuestionable. Debido al potencial de mejora de la IA, los contenidos utilizados son anteriores a 2021. Todos los textos utilizados contenían un mínimo de 600 caracteres, ya que los textos de menor longitud no pueden clasificarse de forma fiable como IA o humano. Esta es también la razón por la que nuestro Detector de IA no proporciona evaluaciones sobre textos de menos de 600 caracteres.
Proceso utilizado para recopilar datos humanos escritos
Nuestro equipo se esforzó por evitar el uso de datos preexistentes de fuentes externas para garantizar la calidad del conjunto de datos. Nuestra observación fue que la gran mayoría de los grandes conjuntos de datos populares disponibles en línea (The Pile, Common Crawl, etc.) y los conjuntos de datos de referencia de la competencia no estaban «limpios». Tras una inspección más detallada de estos grandes conjuntos de datos, nuestro equipo descubrió que contenían varios textos cuyo formato no era correcto, que eran ilegibles, que contenían varios caracteres irreconocibles o que tenían textos en varios idiomas que contenían caracteres extranjeros (sirílico, chino, hangu, árabe).
También nos aseguramos de que los datos utilizados para la formación fueran anteriores a 2021. Se ha informado de que varias fuentes reputadas, incluida Wikipedia, han sido actualizadas con contribuciones generadas por IA. 1 .
Nos aseguramos de que todo el contenido de nuestro conjunto de datos estuviera correctamente codificado (UTF-8), para evitar cualquier malentendido de los datos introducidos en el modelo.
Cada entrada de datos se verificó, se codificó correctamente, era legible y no contenía idiomas ni caracteres extranjeros.
Proceso de recopilación de datos sintéticos/generados por IA
Paralelamente, construimos un conjunto de datos generado por IA de 5.000 textos generados con la mayoría de las principales herramientas de escritura de IA con una API disponible públicamente en el momento de la prueba, incluidas GPT 3.5 Turbo, GPT 4, GPT 4 Turbo, Claude V1 y Claude V2.
Algunos elementos clave para garantizar que nuestro índice de precisión sea válido:
- Para cada LLM, se utilizaron varios mensajes e instrucciones en múltiples campos para variar los resultados y reflejar el contenido escrito por humanos.
- Se utilizaron multitud de ajustes de temperatura para generar una amplia gama de estilos de datos sintéticos.
Por último, nuestro equipo tuvo que examinar cada texto que entraba en nuestro conjunto de datos de 10.000 para asegurarse de que el contenido era aceptable. Puede encontrar aquí el conjunto de datos completo utilizado para nuestra evaluación más reciente del índice de precisión. Para su comodidad, está disponible en formato .csv y .jsonl.
¿Qué considera Winston AI como escritura sintética? (¿y qué es la escritura humana?)
Nos hemos enfrentado a varios casos de uso. Esto es lo que Winston AI cree que es contenido AI y lo que no lo es:
- Redacción y edición humanas: Contenido humano
- Redacción humana y correcciones realizadas con Grammarly (legado): Contenido humano
- Investigación y esbozo de IA, Escrito por humanos: Contenido humano
- Esquema generado por la IA, escrito por un humano y luego reescrito por la IA: contenido de la IA
- Escrito por humanos y reescrito con una herramienta de redacción de IA: Contenido AI
- Generado con IA y editado por un humano: Contenido de IA
- Generado con IA y reescrito por un «AI Humanizer»: Contenido de IA
- Generado o editado con Grammarly Go: Contenido AI
- Generado con IA sin ajustes humanos: Contenido de IA
Para obtener información más detallada sobre cómo Winston AI evalúa los contenidos que han sido revisados con Grammarly, recomendamos nuestro artículo sobre este tema específico.
Métricas de evaluación
Para que una evaluación se considere correcta, nuestro software debe determinar la probabilidad de que el contenido haya sido escrito por humanos o generado por IA con una probabilidad superior al 50%. Para aclarar, si un texto es generado por humanos, necesita una puntuación humana del 51% o superior para que la evaluación se considere precisa. Una puntuación del 50% o menos indicaría una evaluación fallida. Por el contrario, en el caso de los contenidos generados por IA, una evaluación satisfactoria requiere una puntuación humana igual o inferior al 49%. Básicamente, la evaluación depende de una probabilidad mayoritaria: por encima del 50% para los contenidos escritos por humanos y por debajo del 50% para el material generado por IA.
Por tanto, son 3 las evaluaciones que realiza nuestra organización:
- Puntuación de precisión de detección de IA: Describe nuestra capacidad para evaluar los contenidos generados por IA con un porcentaje probabilístico.
- Puntuación de la precisión de la detección humana: Describe nuestra capacidad para evaluar contenidos generados por humanos con un porcentaje probabilístico.
- Puntuación global: Nuestra media ponderada al determinar el contenido generado por IA y el contenido humano.
Resultados y margen de error
Nuestras puntuaciones de precisión se obtuvieron ejecutando nuestro conjunto de datos principal de 10.000 textos proporcionado anteriormente a través de nuestro modelo de detección de IA patentado.
En cuanto a nuestra puntuación de precisión en la detección de IA, la solución de Winston AI fue capaz de detectar contenidos generados por IA con una precisión del 99,98%.
En cuanto a nuestra puntuación en precisión de detección humana, nuestras exhaustivas pruebas revelaron que Winston AI puede identificar texto generado por humanos con una tasa de precisión del 99,50%.
En conjunto, esto significa que nuestra media ponderada (puntuación global) es del 99,74%. Con una muestra tan grande, nuestro margen de error es muy pequeño, de apenas el 0,0998%.
| Precisión de la IA | AI MoE | IA F1 | Precisión humana | ME humano | F1 humano | Precisión global | Total ME |
|---|---|---|---|---|---|---|---|
| 99.98 | 0.0392 | 0.997 | 99.5 | 0.196 | 0.997 | 99.74 | 0.0998 |
Mayores puntuaciones de precisión en LLM
| GPT 3.5 Turbo | GPT 4 | GPT 4 Turbo | Claude 1 | Claude 2 |
|---|---|---|---|---|
| 100.00% | 100.00% | 100.00% | 99.63% | 100.00% |
La tabla anterior muestra nuestra precisión en la detección de modelos lingüísticos específicos populares.
Precisión de los contenidos escritos por personas
| Ficción | Documentos médicos | Poemas | Críticas de películas | Noticias / Blog | Discursos | Wikipedia | Stack Overflow | Recetas | Ensayos / Tesis | |
|---|---|---|---|---|---|---|---|---|---|---|
| 99.09% | 100.00% | 98.85% | 100.00% | 99.56% | 100.00% | 100.00% | 99.15% | 98.05% | 100.00% | 100.00% |
La tabla anterior muestra nuestra precisión en la detección de tipos específicos de contenido escrito por personas (detección de personas).
Comparación de versiones
| Versión | Precisión de la IA | Precisión humana | Puntuación global |
|---|---|---|---|
| 3,0 «Luka» | 99.98% | 99.5% | 99.74% |
| 2.0 | 99.6% | 98.4% | 99% |
La tabla anterior muestra la progresión de nuestras puntuaciones de precisión desde nuestra última gran actualización.
Matriz de confusión
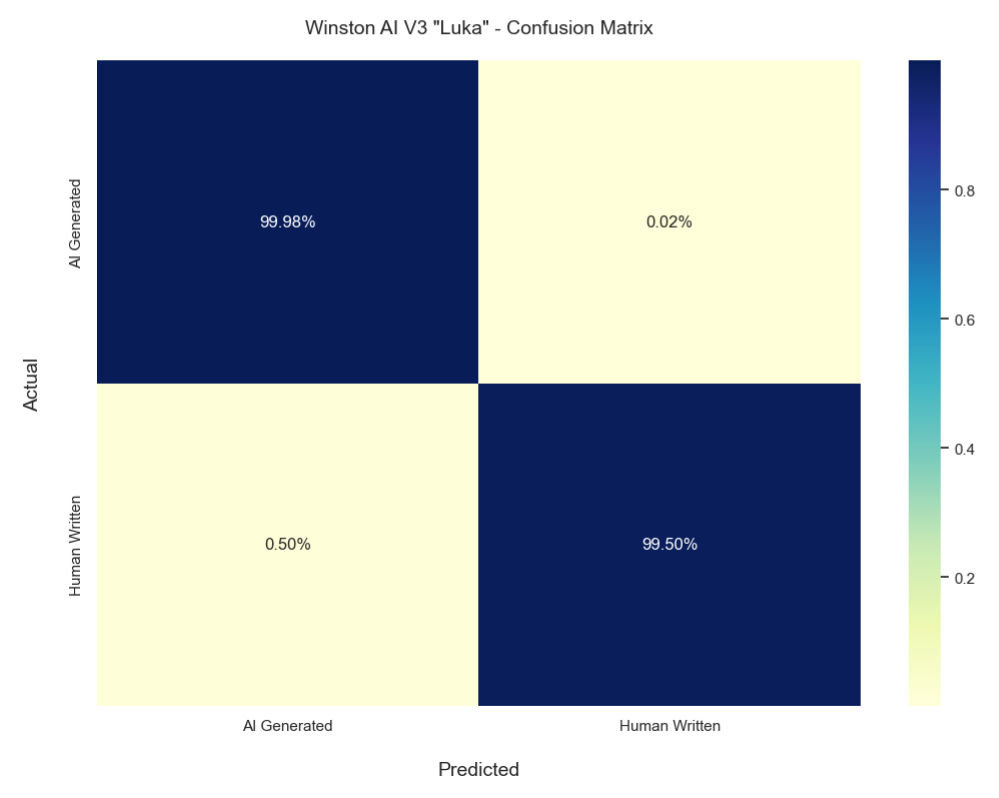
El gráfico anterior muestra la matriz de confusión de nuestro último modelo de detección de IA.
Conclusión
Winston AI ha tomado medidas sin precedentes para aportar transparencia a la cuestión crucial, pero opaca, de los índices de precisión en la detección de contenidos mediante IA. Al hacer públicos todos los detalles y datos que respaldan nuestro índice de precisión, líder del sector con un 99,74%, esperamos inspirar una nueva cultura de apertura e integridad. Los usuarios merecen conocer las verdaderas capacidades de las herramientas que utilizan. A medida que proliferan los contenidos de IA, la necesidad de herramientas fiables para discernir los contenidos sintéticos no hace sino crecer. Nos comprometemos a mantenernos a la vanguardia para ayudar a organizaciones y particulares a mantener la integridad. Si nuestra transparencia sirve de modelo para que otros la sigan, habremos conseguido dar un paso hacia un futuro en el que los usuarios puedan confiar plenamente en los índices de precisión prometidos por las soluciones de detección de IA.
Referencias
PREGUNTAS FRECUENTES
A medida que prolifera la IA, es crucial disponer de herramientas fiables para detectar contenidos sintéticos. Pero no todos los detectores son iguales. Las promesas opacas de precisión contribuyen poco a generar confianza en el usuario. Al hacer públicos todos los datos sobre nuestra tasa del 99,74%, líder del sector, esperamos inspirar apertura y confianza.
Cuidados meticulosos. 10.000 textos de diversos géneros. 5.000 humanos, 5.000 IA. Generado utilizando muchas de las principales herramientas de IA, como ChatGPT (GPT 3.5 Turbo, GPT 4 y GPT 4 Turbo), Claude 1 y Claude 2. Cada pieza es examinada por humanos. Un nivel de calidad y transparencia sin precedentes.
Puntos de referencia claros y rigurosos. Textos AI identificados correctamente como AI en un 99,98%. Textos humanos identificados correctamente como humanos en un 99,50%. Una media ponderada transparente del 99,74%. Un margen de error de apenas el 0,0998%. La prueba está en los datos.
Confianza a través de la transparencia. Los usuarios merecen conocer las verdaderas capacidades de una herramienta. Las afirmaciones opacas inspiran dudas. Al hacer públicos todos los hechos, pretendemos establecer un nuevo estándar de integridad en la detección de IA.
Aquí mismo. Creemos que la transparencia es la base de la confianza entre una empresa y sus usuarios. Explore los datos que impulsan nuestra precisión líder en el sector.
@misc{Lavergne_2023, title={A deep dive into our best in class accuracy rate}, url={https://gowinston.ai/setting-new-standards-in-ai-content-detection/}, journal={Winston AI}, publisher={Winston AI}, author={Lavergne, Thierry}, year={2023}, month={Dec}}